Retrieval-Augmented Generation (RAG) has become the cornerstone of many real-world Generative AI deployments, offering important advantages over relying solely on the pretrained knowledge of a particular Large Language Model (LLM).
In this blog post, we’ll explore how to integrate a RAG application with FuriosaAI’s RNGD, a high-performance, energy-efficient inference accelerator for LLMs and agentic AI models.
Furiosa’s RNGD currently delivers a throughput of 3,200 to 3,300 tokens per second (TPS) when running the Llama 3.1 8B model at FP8 precision. A single RNGD server can be tuned to meet different use cases (for example serving up to 60 concurrent users with throughput of 40 TPS per user). Each RNGD maintains a radically efficient 180W power profile with 48GB of HBM3 memory capacity. And these performance and efficiency numbers will continue to improve as we ship additional optimizations.
Crucially, RNGD delivers these numbers using a fraction of the power consumed by today’s GPUs. That means simpler, more cost-effective RAG applications, making it an ideal AI chip for on-prem solutions or in data centers.
The promise and challenges of RAG
RAG offers powerful capabilities for running Generative AI applications that leverage vast amounts of up-to-date, domain-specific, and private information.
For example, a RAG application might enable a company’s employees to query policy manuals, technical specifications, and other internal documentation. It can also power a customer service chatbot that accesses the latest production information, FAQs, and troubleshooting materials.
RAG is well-suited for critical tasks such as compliance and legal research, as well as semantic search tailored to a company’s particular use case. Enterprises can deploy RAG applications either in the cloud or entirely on their own servers, enhancing data privacy and security when run on-premises.
Advantages of RAG over LLM-only approaches include:
- Domain specificity: Grounding responses in your business’s specific data makes them more useful.
- Reduced hallucinations: Providing evidence makes outputs more reliable and easily verifiable.
- Up-to-date knowledge: Easily update, modify, or remove information from a knowledge base.
- Scalable knowledge: Leverage vast document collections, far exceeding the practical limits of an LLM’s training data.
Domain specificity: Grounding responses in your business’s specific data makes them more useful.
Reduced hallucinations: Providing evidence makes outputs more reliable and easily verifiable.
Up-to-date knowledge: Easily update, modify, or remove information from a knowledge base.
Scalable knowledge: Leverage vast document collections, far exceeding the practical limits of an LLM’s training data.
However, deploying RAG systems presents several engineering challenges because it requires LLMs, embedding models, and vector databases all working together to respond to each query:
- Complexity in creating, updating, and scaling
- Potential latency issues affecting usability
- Energy consumption impacting infrastructure costs
Complexity in creating, updating, and scaling
Potential latency issues affecting usability
Energy consumption impacting infrastructure costs
Implementing RAG with RNGD: A Practical Example
Furiosa’s RNGD chip is designed to address these challenges head-on. It has a full stack, including a general compiler, advanced optimization tools, a serving framework, and high-level PyTorch 2.x integration. RNGD offers high performance, breakthrough power efficiency, and seamless integration with existing RAG frameworks and tools.
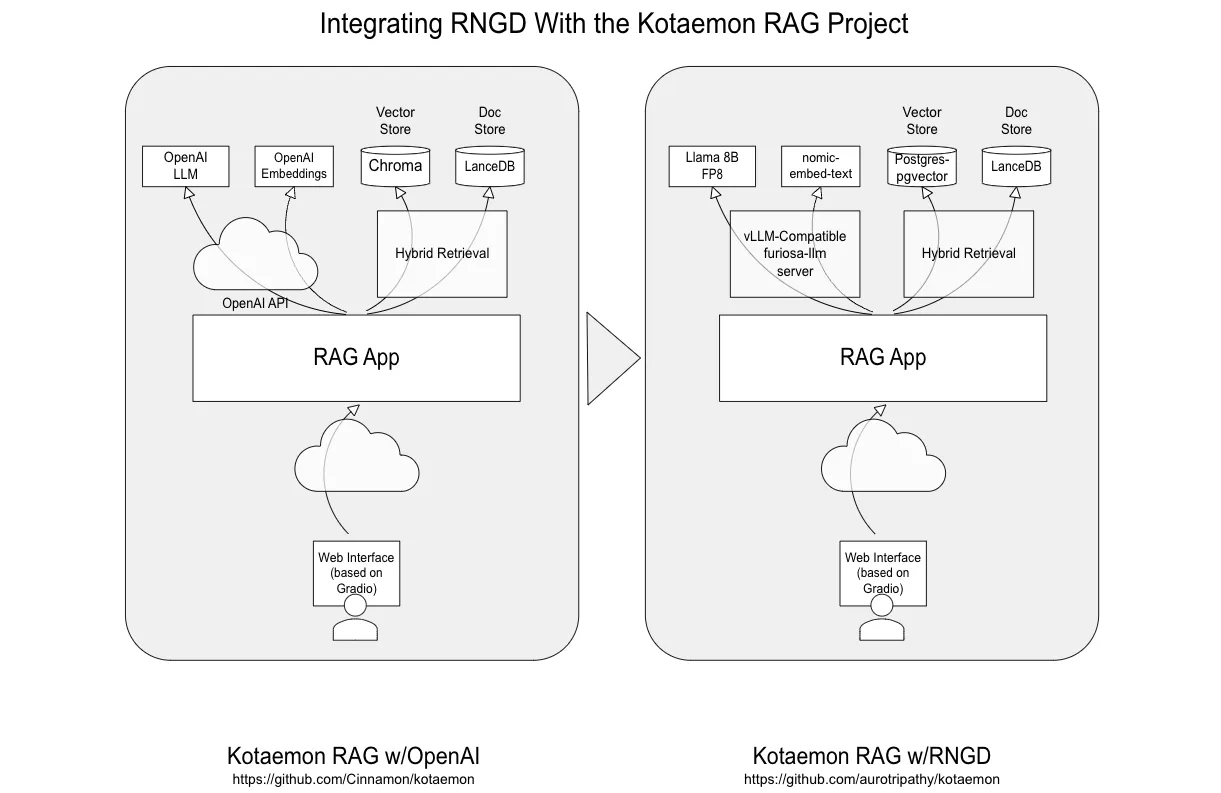
To illustrate the ease of integration, let’s examine a real-world example using Kotaemon, a popular open-source RAG project with 21K+ GitHub stars.
The default Kotaemon setup uses OpenAI for both text generation and embeddings. Instead of the OpenAI REST call to the cloud, we’ll manage requests locally with RNGD, demonstrating a simple, configuration-based integration. (Visit our Developer Center for documentation on how to launch RNGD server locally.)
Integration Steps:
- Configuration: Kotaemon uses a Gradio interface for its UX and resource management. To integrate RNGD, simply modify the LLM endpoint configuration:
- Set the base URL to your RNGD server.
- Specify the LLM. (In this case we will use Llama 3.1 8B.) This is done by editing the config.yaml file in Kotaemon.
- That’s it. No other code changes are required for basic integration.
- Set the base URL to your RNGD server.
- Specify the LLM. (In this case we will use Llama 3.1 8B.) This is done by editing the config.yaml file in Kotaemon.
- That’s it. No other code changes are required for basic integration.
Set the base URL to your RNGD server.
Specify the LLM. (In this case we will use Llama 3.1 8B.) This is done by editing the config.yaml file in Kotaemon.
That’s it. No other code changes are required for basic integration.
llm_endpoint:
base_url: "http://<RNGD_SERVER_IP>:8080" # Replace with your RNGD server IP and port
model: "llama-3.1-8b"- Document ingestion. For this example we ingested the DeepSeek-R1 paper. Kotaemon handles chunking, embedding generation, and storage of document chunks and embeddings:
- Chunking the document into manageable pieces. Koteamon uses a sliding window approach for chunking, with a chunk size of 500 tokens and an overlap of 50 tokens.
- Converting each chunk into a vector representation using an embedding model (in this case, nomic-embed-text, which can be served via RNGD’s furiosa-llm server or via an Ollama server in this case, nomic-embed-text served locally via an Ollama server). Koteamon communicates with the Ollama server via its REST API to generate embeddings using the nomic-embed-text model. Connection details are configured in the config.yaml file.
- Storing the text chunks in LanceDB and the embeddings in Postgres-PGVector. The database connection details are also configured in the config.yaml file.
- Query processing and Response Generation:
- The user’s query is converted to an embedding using nomic-embed-text.
- A vector search finds the document chunks that are most relevant to the query embedding, then combines the chunks to serve as context for the LLM. Koteamon uses the cosine similarity algorithm for vector search in PGVector. It retrieves the top k most relevant chunks based on a cosine similarity score.
- The combined context and the original query are inputted into the Llama 3.1 8B model running on RNGD, which efficiently processes the information and generates a response.
- For multi-turn conversations, the previous context is passed into the model as well. Koteamon maintains a conversation history and appends the previous context to the new query. The size of the context window is configurable.
- Chunking the document into manageable pieces. Koteamon uses a sliding window approach for chunking, with a chunk size of 500 tokens and an overlap of 50 tokens.
- Converting each chunk into a vector representation using an embedding model (in this case, nomic-embed-text, which can be served via RNGD’s furiosa-llm server or via an Ollama server in this case, nomic-embed-text served locally via an Ollama server). Koteamon communicates with the Ollama server via its REST API to generate embeddings using the nomic-embed-text model. Connection details are configured in the config.yaml file.
- Storing the text chunks in LanceDB and the embeddings in Postgres-PGVector. The database connection details are also configured in the config.yaml file.
Chunking the document into manageable pieces. Koteamon uses a sliding window approach for chunking, with a chunk size of 500 tokens and an overlap of 50 tokens.
Converting each chunk into a vector representation using an embedding model (in this case, nomic-embed-text, which can be served via RNGD’s furiosa-llm server or via an Ollama server in this case, nomic-embed-text served locally via an Ollama server). Koteamon communicates with the Ollama server via its REST API to generate embeddings using the nomic-embed-text model. Connection details are configured in the config.yaml file.
Storing the text chunks in LanceDB and the embeddings in Postgres-PGVector. The database connection details are also configured in the config.yaml file.
- The user’s query is converted to an embedding using nomic-embed-text.
- A vector search finds the document chunks that are most relevant to the query embedding, then combines the chunks to serve as context for the LLM. Koteamon uses the cosine similarity algorithm for vector search in PGVector. It retrieves the top k most relevant chunks based on a cosine similarity score.
- The combined context and the original query are inputted into the Llama 3.1 8B model running on RNGD, which efficiently processes the information and generates a response.
- For multi-turn conversations, the previous context is passed into the model as well. Koteamon maintains a conversation history and appends the previous context to the new query. The size of the context window is configurable.
The user’s query is converted to an embedding using nomic-embed-text.
A vector search finds the document chunks that are most relevant to the query embedding, then combines the chunks to serve as context for the LLM. Koteamon uses the cosine similarity algorithm for vector search in PGVector. It retrieves the top k most relevant chunks based on a cosine similarity score.
The combined context and the original query are inputted into the Llama 3.1 8B model running on RNGD, which efficiently processes the information and generates a response.
For multi-turn conversations, the previous context is passed into the model as well. Koteamon maintains a conversation history and appends the previous context to the new query. The size of the context window is configurable.
While the integration primarily involves config changes, here are simplified code snippets to illustrate the key steps:
import requests
import json
def generate_response(query, context=""):
payload = {
"query": query,
"context": context
}
headers = {"Content-Type": "application/json"}
response = requests.post("http://<RNGD_SERVER_IP>:8080/generate", headers=headers, data=json.dumps(payload))
response.raise_for_status()
return response.json()["response"]
# Example usage
query = "What is DeepSeek-R1 about?"
response = generate_response(query)
print(response)
# For multi-turn conversations:
previous_context = "DeepSeek-R1 is a reasoning model."
query = "Tell me more about its applications."
response = generate_response(query, previous_context)
print(response)As you can see, the code modifications are minimal. The core RAG logic remains unchanged; the integration focuses on configuring the LLM endpoint to use RNGD-hosted furiosa-llm, a vLLM compatible LLM server.
This example, which uses the DeepSeek-R1 paper as its information source, showcases the flexibility of combining RNGD with Koteamon. By easily swapping out different LLMs, embedding models, vector stores, and document stores, developers can tailor the system to their specific needs. The use of PGVector provides a scalable solution for handling large document collections.
Key Benefits of RAG with RNGD
- Dynamic Data Integration: RAG models continuously integrate data from external knowledge bases, providing up-to-date and relevant information
- Customized Response Generation: Responses are tailored to match specific user queries, improving user satisfaction and engagement
- Reduced Bias and Error: By basing responses on verified external data sources, RAG minimizes inaccurate outputs
- Scalability Across Domains: RAG’s flexible architecture allows adaption to various sectors without extensive fine-tuning
- Resource Efficiency: RAG models retrieve only relevant data chunks, which can reduce computational load and improve response times. (In some cases – such as a larger vector DB system, data processing modules, embedding model and custom orchestration – a RAG system can require more resources than an LLM-only approach.)
Future work will explore integration with other vector databases and embedding models to maximize the performance and flexibility of a RNGD-powered RAG system.
Written by Auro Tripathy, Principal Solutions Architect
Written by
The Furiosa Team



