
Furiosa Software
The software stack activating RNGD performance
A unified software stack and execution environment engineered to map complex neural networks directly to silicon. Build, optimize, and scale models with predictability across Furiosa hardware.
Radical efficiency across compilation and execution
Our software optimizations span the entire lifecycle of inference, combining ahead-of-time compilation with high-efficiency runtime serving systems to maximize your infrastructure density.

Global optimization via holistic search

High-throughput, low-latency scheduling
The GPU bottleneck: Intractable search spaces



Traditional general-purpose GPU architectures rely on an unconstrained execution paradigm that forces compilers to guess the optimal paths for multi-dimensional tensor workloads. Because the hardware execution remains fundamentally fluid and non-deterministic, the compiler is forced into an intractable search space, relying on brittle, hand-crafted heuristics and manual kernel tuning to achieve peak utilization. This structural mismatch leaves hardware underutilized.
The tensor-native advantage: Global optimization via shapes and tactics


By co-designing our software stack alongside a first-principles Tensor Contraction Processor (TCP) architecture, we eliminate compiler guesswork. The predictable, structured nature of the silicon gives the compiler full architectural visibility into memory allocations and instruction scheduling. Using structural shapes and execution tactics, the compiler evaluates a clean, bounded search space to automatically generate globally optimized execution graphs.
TCP advantages: Accurate cost model for compiler optimizations


The ultimate measure of a computing platform in the era of AI is how it performs under production-scale environments for the inference needs of enterprises. While legacy GPU architectures suffer from volatile execution paths that introduce massive tail-latency spikes, our tensor-native compiler leverages a mathematically precise hardware cost model to guarantee absolute execution determinism. As shown in the performance distribution, workloads execute with a tight, predictable latency profile. This elimination of tail-latency allows enterprise infrastructure teams to maximize service density, packing concurrent workloads tightly within fixed power envelopes without risking strict operational SLAs.
Drop-in GPU replacement available. Migrate your stack today
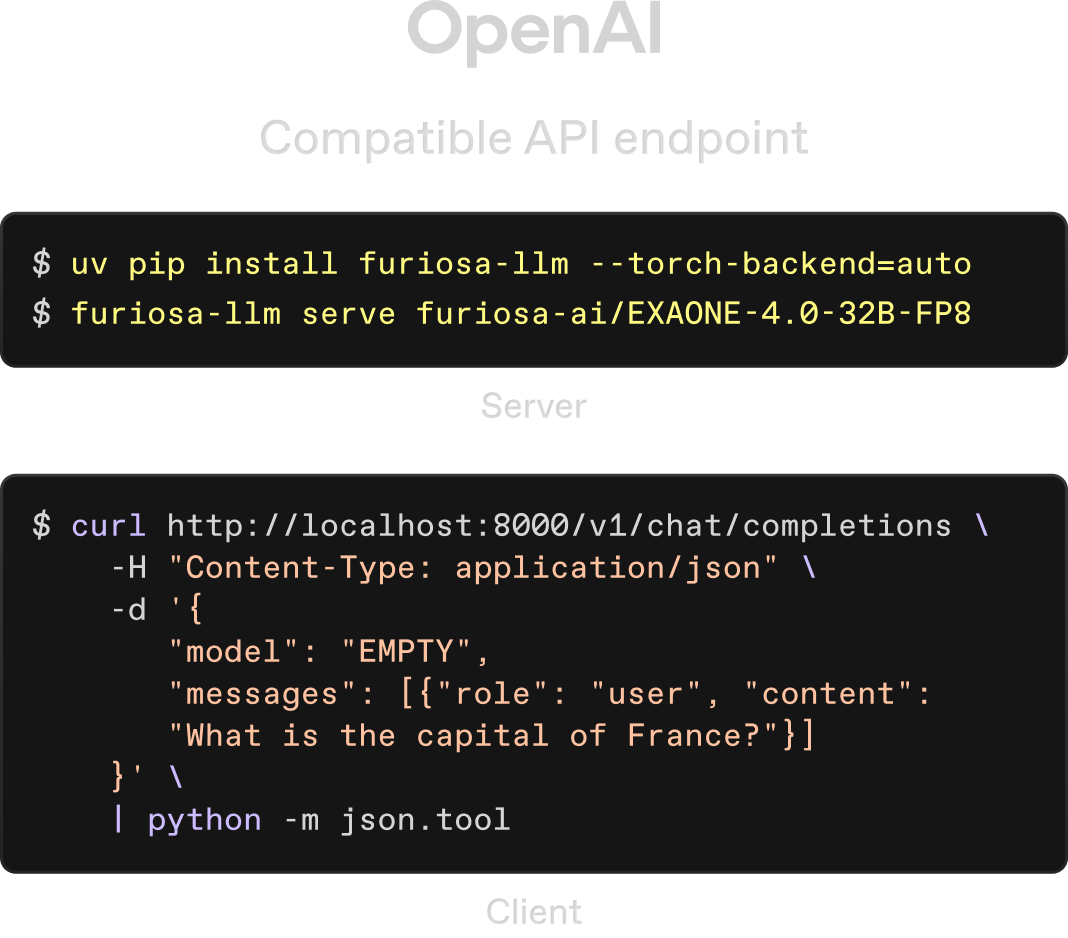

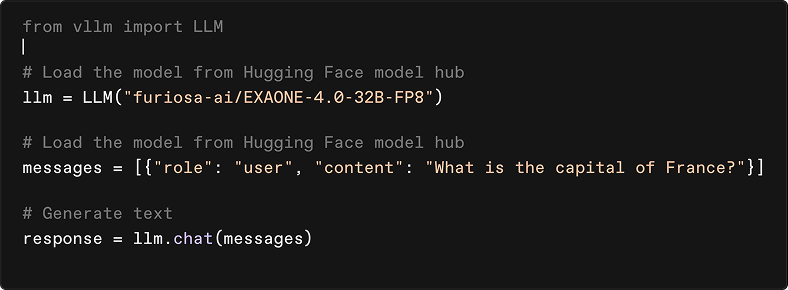
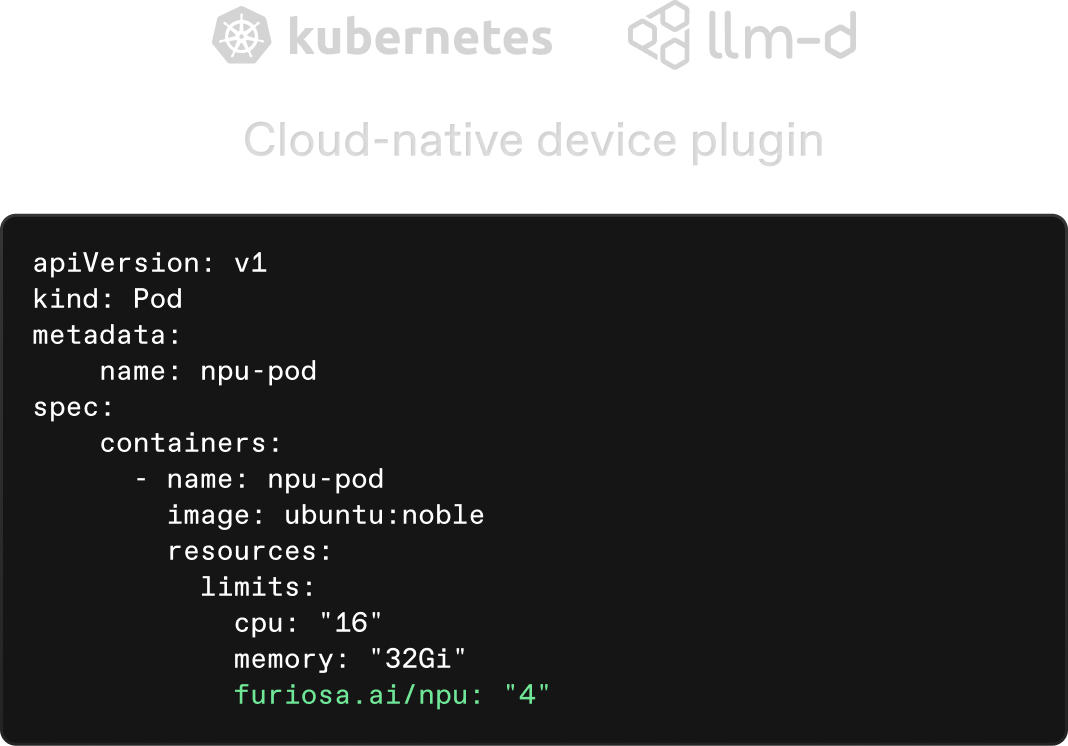
Software compatibility across the modern AI stack, including modern LLM serving APIs, the vLLM interface, and seamless integration with existing cloud infrastructure.
Reference applications available on GitHub

Agent

RAG system

Start building with Furiosa
Blog
.png)
FuriosaAI and Samsung SDS Launch Korea’s First Domestic NPUaaS to Expand Enterprise AI Access
News
FuriosaAI and Samsung SDS Launch Korea’s First Domestic NPUaaS to Expand Enterprise AI Access

Experience RENEGADE Summit 2026
News
Experience RENEGADE Summit 2026

RNGD outperforms RTX Pro 6000 with the latest SDK
Technical Updates
RNGD outperforms RTX Pro 6000 with the latest SDK
