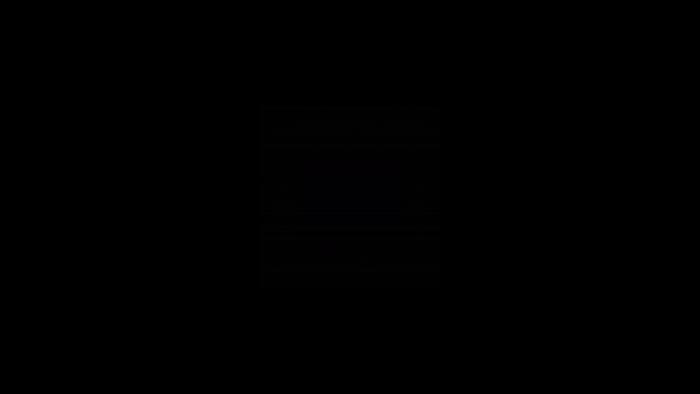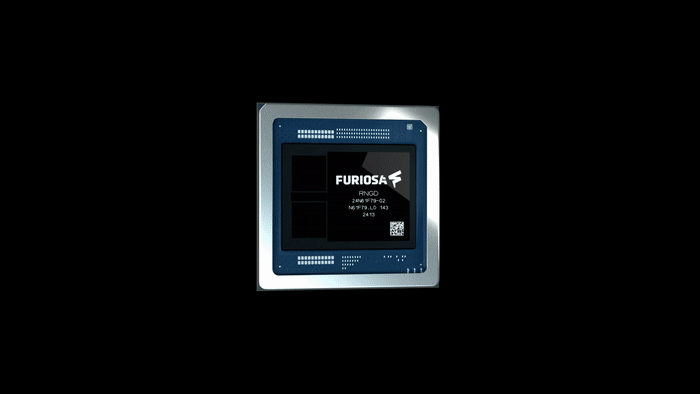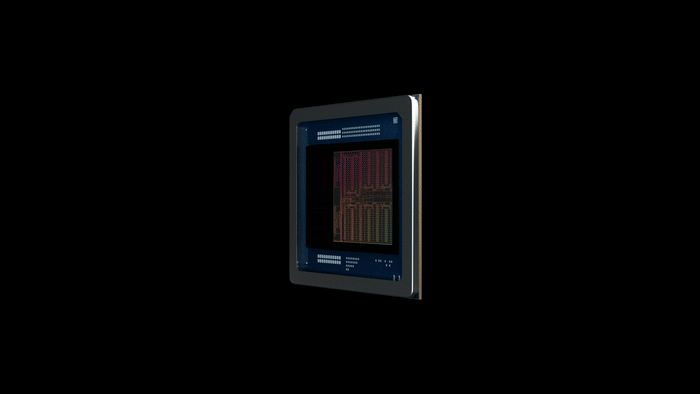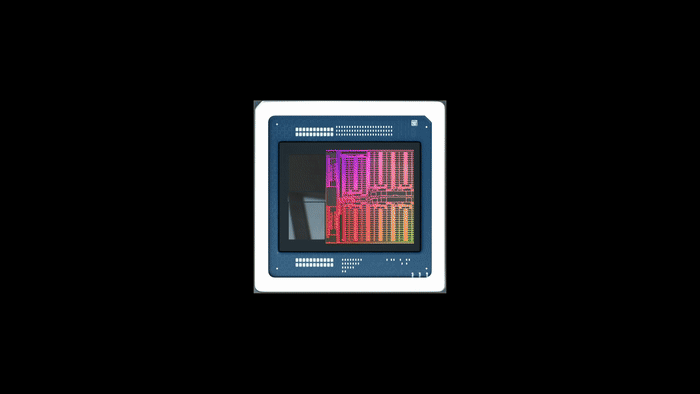
We're seeing a lot of new visitors coming to furiosa.ai over the past week…
So, we thought it was a good time to share the vision that is driving FuriosaAI and explain how it aligns with where the field of AI is today, with exciting advances like DeepSeek dominating the headlines.
The AI landscape today is shifting toward inference compute
Four important trends are shaping the direction of Generative AI:
- AI systems are becoming more and more efficient, with smaller models equaling or exceeding the performance of previous iterations. Industry leaders have noted this looks like a clear manifestation of Jevons paradox, which holds that increased efficiency leads to increased consumption of a resource, not less.
- It’s also becoming more and more useful. Already in 2025 we’ve seen tremendous progress in agentic AI, multimodal AI, advanced reasoning systems, and domain-specific applications in medicine and scientific research. To harness these advances in production, data centers will need inference compute to run the models.
- AI agents and reasoning models rely more on inference-time compute for chain-of-thought reasoning, multiple smaller models, retrieval-augmented generation (RAG), tool use, and API calling.
- GPUs are consuming more and more power, which constrains how AI can be used. The last generation of advanced GPUs used 40kW per rack. The current generation uses 60kW or more.
We believe these trends will all only accelerate in 2025 and beyond.
The first three trends combined signal the arrival of the Age of Inference. Running advanced AI services in production for millions or even billions of people requires a huge and growing amount of compute. So the most acute AI hardware challenge isn’t chips to train new models from scratch, but rather inference workloads in production.
Combined with the reality of GPUs’ enormous power consumption, this means the industry urgently needs new, much more scalable ways to accelerate AI applications.

A quick history
When we founded Furiosa eight years ago, the AI landscape looked very different. Transformer models were an exciting new research area. Chatbots and conversational AI tools were clunky and ineffective. Even the most advanced AI models were a fraction of the size of today’s.
We didn’t predict the arrival of ChatGPT or the remarkable efficiency gains of DeepSeek-R1. However, we recognized the immense potential of Transformers and LLMs (and believed future innovations would eventually supplant Transformers). And we were inspired and excited early on by the effectiveness of LLM scaling laws. So, we chose to architect RNGD specifically for a future in which the world would need huge quantities of powerful, versatile inference compute.
Furiosa was built from the ground up to address this need. We focused on delivering three things:
- Performance -- Hardware isn’t much good if it won’t run the best AI models with excellent throughput and low latency. This means delivering not just sufficient compute, but also memory bandwidth to accommodate models with many billions of parameters.
- Programmability -- High-performance AI hardware isn’t useful in the real world if it is difficult or impossible to use with a very wide range of AI models, use cases, and deployment scenarios. Some GPUs and some AI chips have achieved great numbers on a few specific benchmarks, only to have performance drop dramatically when you try a different model, a smaller batch size, or a different context length. We needed to avoid that fate. Co-designing our hardware and software together from the start has been key to achieving this. RNGD has a full stack, including a general compiler, advanced optimization tools, a serving framework, and high-level PyTorch 2.x integration.
- Power Efficiency -- Even an amazing AI chip is of limited value if it consumes 1,000W or more of power. This kind of energy consumption isn’t sustainable. It isn’t cost-effective for businesses. It isn’t scalable to new applications and new kinds of use cases. 1,000W chips aren’t even compatible with the vast majority of today’s data centers, which aren’t built to deliver that much electricity or provide enough cooling.
Achieving the Performance + Programmability + Power Efficiency trifecta required a new approach to designing AI chips.
You can read more about our Tensor Contraction Processor (TCP) architecture in our ISCA 2024 paper, but in short, we built it around tensor contraction (rather than matmul) as the primitive operation.
AI data typically takes the form of multidimensional tensors. Preserving the data’s structure enables us to manage data movement much more efficiently and easily than GPUs do. Data movement consumes loads of energy, so less data movement means less energy consumption. Traditional GPUs and other AI accelerators, by contrast, struggle with diverse tensor shapes, meaning that in production many of their compute units sit idle and data is shuffled around unnecessarily. (Seriously, read the paper, please. Or at least our blog post on TCP.)
The Performance + Programmability + Power Efficiency trifecta also required us to use state-of-the-art technology in our chips. So, by partnering with industry leaders, we integrated advanced technology like a 5nm node and HBM3 into RNGD.
The result is a chip that delivers 512 TFLOPS of compute at FP8 precision and 1.5TB/s of memory bandwidth, with a 180W TDP.

A real product, not just a render
RNGD is not a future promise; it’s a product that is currently sampling with customers. We achieved full bring-up last June, just weeks after receiving the first silicon from our foundry partner, TSMC. We were running industry standard models like Llama 3.1 70B just a few weeks later. And we officially unveiled RNGD in August at the Hot Chips conference on the Stanford University campus.

Since then, we’ve continued to refine our software stack. Rather than excessively boosting per-user performance, the company aims to maintain performance levels exceeding typical text-reading speeds (10 to 20 TPS or higher) while optimizing for multi-user environments and achieving a balanced performance approach. Furiosa’s RNGD delivers a throughput of 3,200 to 3,300 Tokens per Second (TPS) when running the Llama 3.1-8B model. In single-user scenarios, RNGD consistently delivers 40 to 60 TPS performance. These numbers will continue to improve as we ship additional software enhancements.
Crucially, RNGD delivers these numbers using a fraction of the power consumed by today’s GPUs. That means simpler, more cost-effective inference.
Solving planet-scale inference
The dominant industry trends – the arrival of agentic AI and reasoning models, the increased efficiency driving demand for AI, the growing importance of inference-time compute, and the fundamental limitations of GPUs – all point to a critical need: purpose-built AI accelerators that deliver the trifecta of performance, programmability, and power efficiency.
This isn't a theoretical problem; it's a practical bottleneck that impacts businesses today.
We’ll wrap up this blog post recapping the main point, but more efficiently: AI is advancing quickly. That accelerates the demand for inference. GPUs are too power hungry to satisfy this demand, so the industry must move forward.
Our mission is to power that shift.
Written by
The Furiosa Team



