
One of the biggest challenges for people learning English is the language’s vast number of idioms and words with multiple meanings. For example, the word “take” has different meanings in “take a nap” and “take a taxi,” and the correct translation will depend on that context. Often, the correct translation hinges on the meaning of an entire passage, such as the word “take” in this example: “Many people think naps are only for children or for senior citizens, but I take one every day."
ePopSoft, which makes the most widely used English instruction app in South Korea, created a new app called SayVoca Dictionary to help people learn these tricky words and phrases much more easily. The service is powered by Furiosa’s Gen 1 Vision NPU accelerator card for computer vision applications.
With ePopSoft’s new app, people can simply point their phone camera at a passage of text and immediately learn the correct meaning of each word or phrase in that specific context. Rather than listing all the possible meanings of “take,” the app presents just the one that’s contextually relevant. SayVoca believes this is the key to a more enjoyable and effective language-learning tool.
But to deliver a good experience, the SayVoca Dictionary app needs to reliably recognize and understand long passages of text in smartphone photos taken in a wide range of tricky real-world situations. If the app doesn’t recognize when a text passage is broken up into multiple columns or divided across two pages in a photo of an open book, it will produce an error-ridden translation. These mistakes will lead to a poor user experience that might drive people to abandon the app altogether – and have a lower opinion of ePopSoft in general.
With Furiosa's Gen 1 Vision NPU at the heart of a complex data pipeline, ePopSoft’s SayVoca Dictionary language learning app is available now. The app currently has a 4.3-star rating in Apple's App Store.

Challenges beyond everyday OCR
Optical Character Recognition (OCR) and translation aren’t new technologies, of course. But ePopSoft needed to solve several key challenges in order to create a “smart dictionary” app that understands the precise meaning of each word in context:
- Effective text translation needs to disambiguate words by looking at the meaning not just of the surrounding sentence but often the entire paragraph or page of text.
- In photos taken in real-world situations, text often isn’t presented in a single, clearly defined block; it might be broken up into columns, captions, diagrams, and more.
- Text in photos is often skewed or distorted – for example, when the pages of an open book don’t lie perfectly flat.
- Artifacts (like a smudge on a page) can confuse OCR models.
- In high-resolution smartphone photos, text might take up just a small portion of a particular image. The app needs to work well with these kinds of large, detailed photos while also minimizing latency.
To meet these needs, ePopSoft is using four of the 121 Gen 1 NPUs deployed in the Kakao Cloud as part of a multistage pipeline that also incorporates CPUs.
When a user takes a photo in the SayVoca Dictionary app, an API call request is sent to the Furiosa AI Gen 1 Vision NPU server installed in Kakao Cloud, as shown in the graphic below.
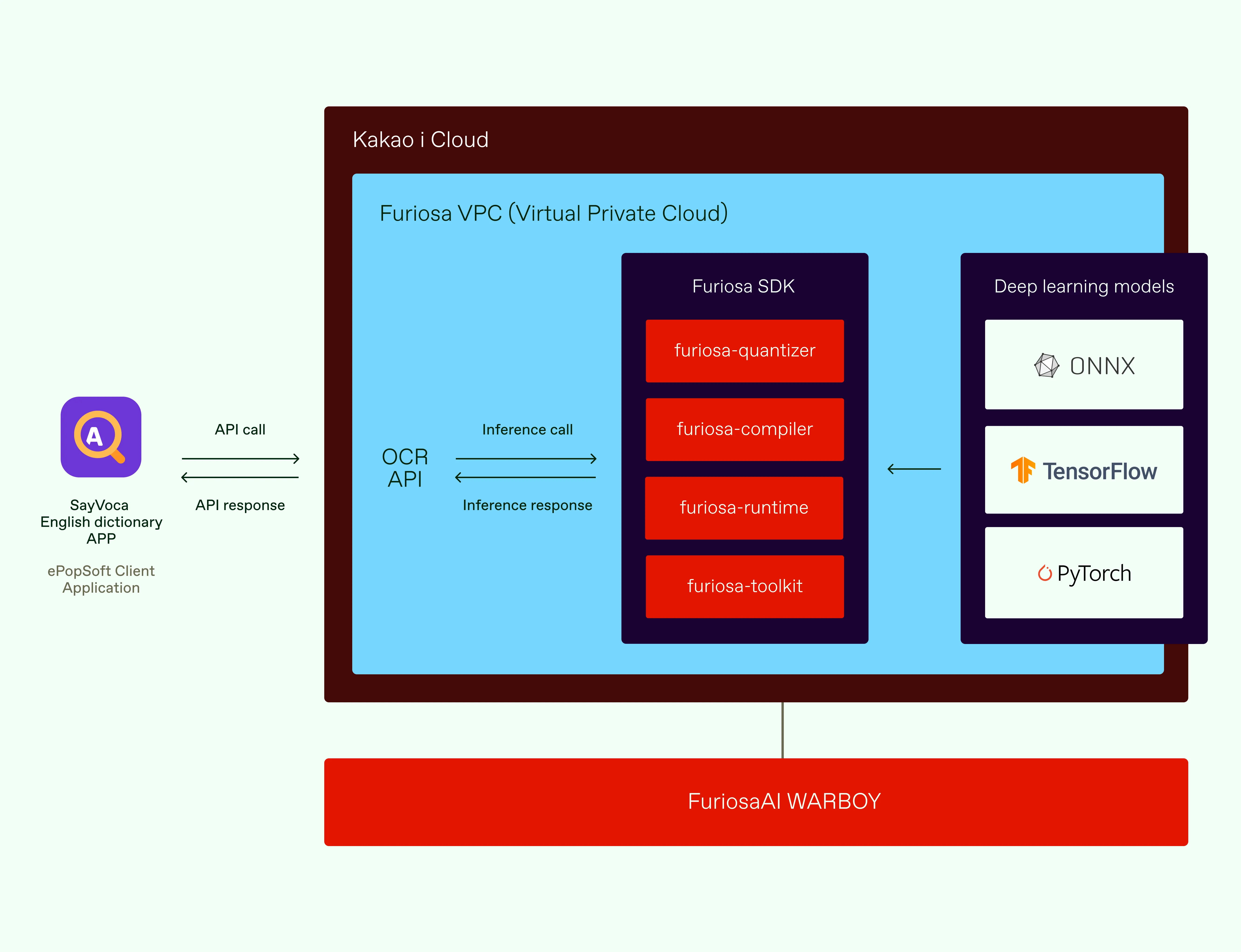
This end-to-end OCR service incorporates several complex steps, including the models running on Furiosa's Gen 1 Vision NPU, OpenVINO using a CPU, ONNXRuntime using a CPU, and even C++ code (i.e., textline detection algorithm).
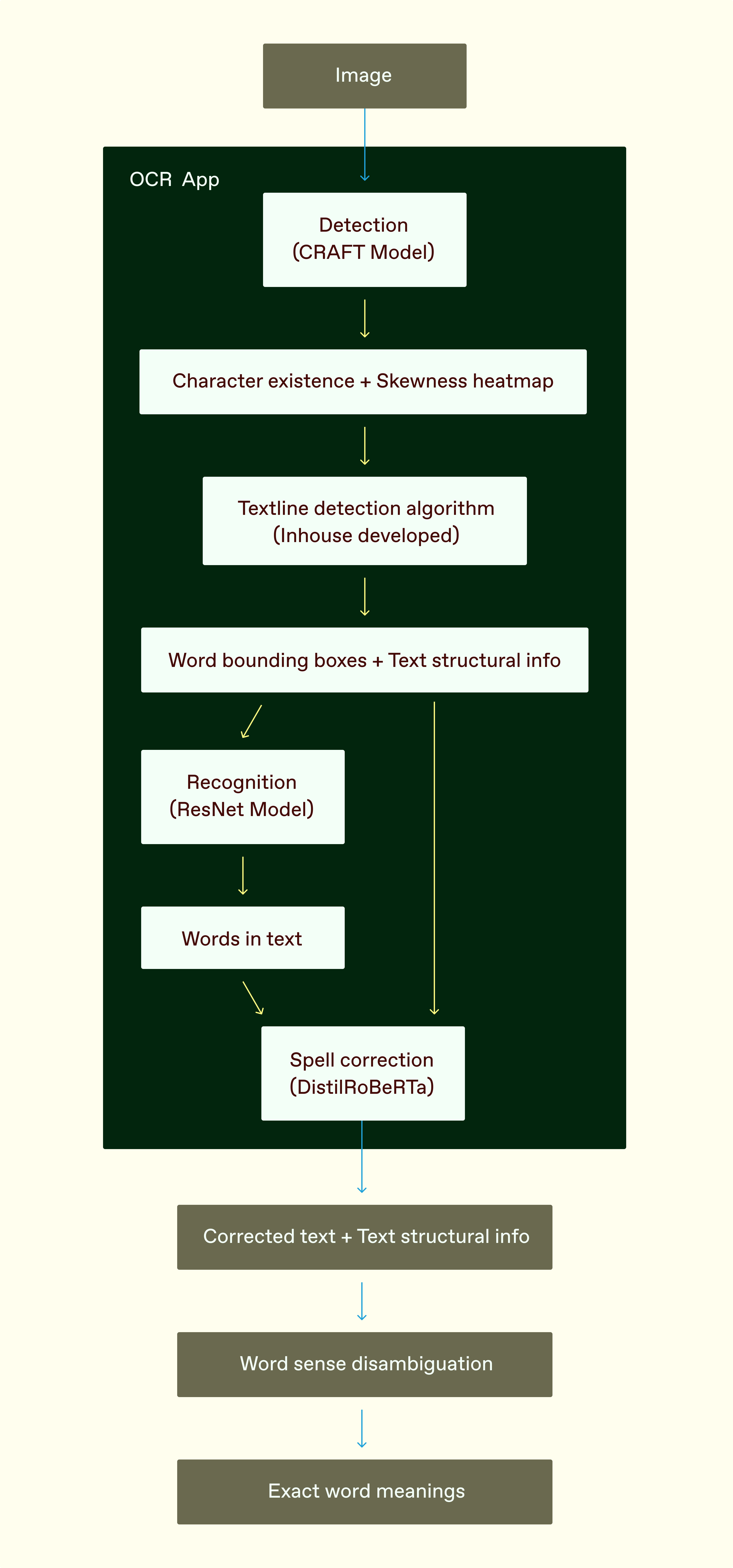
The first step in the pipeline is text detection using the CRAFT model running on the NPU. This model predicts multiple heatmaps, indicating the probability of the existence of characters and spaces between characters, as well as how skewed characters are in the image.
Then, the textline detection algorithm implemented in C++ predicts the text lines and the bounding boxes for characters with structural information.

Once this is done, the text recognition model running on NPU predicts the specific characters in the bounding boxes generated by the textline detector. Recognizing that some words and spelling may be incorrect due to conditions like distorted text or poor lighting, we run a spell correction model DistilRoBERTa running on a CPU via OpenVINO.
Managing a complex pipeline using different runtimes for serving
To power the SayVoca Dictionary app, we needed a way to expose the model pipelines as an online inference API. Even though there are many options for serving frameworks, it is still challenging to combine multiple models using different runtimes and accelerators into a single complex pipeline. furiosa-serving provides great programmability to allow users to build a complicated pipeline easily in Python. Here, we briefly introduce how we organize the complicated pipeline through furiosa-serving.
The following example shows how to serve a model using an ONNX model named “model.onnx” using the endpoint “/models/example.” As you can see, the code is straightforward.
from furiosa.common.thread import synchronous
from furiosa.serving import ServeAPI, FuriosaRTServeModel
# Main serve API
serve = ServeAPI(repository.repository)
# This is FastAPI instance
app: FastAPI = serve.app
# Define a serving app for a single model
class ExampleApplication(FuriosaRTServeModel):
def __init__(self, model: Awaitable[FuriosaRTServeModel]):
self._model = model
async def inference(inputs) -> ExampleResponse:
return await self._model.predict(inputs)
# Initialize the serving app with specifying runtime
example_app = ExampleApplication(
model=serve.model("furiosart")(
"model name",
version="v1.0", # model version
location="path/to/correction/model.onnx", # model path
compiler_config={}, # configurations
),
)
# Define a endpoint and implement how to call the serving app
@app.post("/models/example", response_model=ExampleResponse)
async def example(image: UploadFile = File()) -> AnnotationResponse:
"""Correct wrong texts in annotation."""
result = await example_app.inference(image)
return ExampleResponse(result)A snippet of example code for furiosa-serving.
In this code snippet, ExampleApplication is a custom class that allows users to define an inference pipeline. There is just one simple step to run a single inference using the given model. You can implement your own pipeline with multiple models as follows:
class AnnotationApplication:
def __init__(
self,
detection: Awaitable[FuriosaRTServeModel],
recognition: Awaitable[FuriosaRTServeModel],
):
self._detection = detection
self._recognition = recognition
async def inference(inputs) -> AnnotationResponse:
detected = await self.detection.predict(inputs)
return self.recognition(detected)Also, to use OpenVINO on a CPU, you could initialize an application instance as follows:
class CorrectionApplication:
def __init__(self, model: ServeModel):
self.model = model
self.tokenizer = RobertaTokenizerFast.from_pretrained(
f"path/to/pretrained/roberta-base/tokenizer",
local_files_only=True,
)
async def inference(text: CorrectionRequest) -> CorrectionResponse:
...
correction = CorrectionApplication(
model=serve.model("openvino")(
"correction model name",
version="v1.0",
location="path/to/correction/model",
compiler_config={
"CPU_THROUGHPUT_STREAMS": "2",
"CPU_BIND_THREAD": "NUMA",
},
),
)Handling large images in order to improve text-detection accuracy
A separate challenge is the input size of images for the model. Modern smartphone cameras produce large images (e.g., 4032x2268 pixels) while computer vision models typically use much smaller input images. (224x224 pixels for ResNet and 416x416 for YOLOv5, for example.)
The SayVoca Dictionary pipeline uses a resize step, as is common in smartphone computer vision tasks, but we still needed to make sure the image was large enough to maintain accuracy. A large input image may not fit on a single chip’s SRAM, which could degrade performance as the data spills over into DRAM.
To handle large images efficiently, the SayVoca computer vision pipeline splits large images into a number of smaller ones, and then processes them as a single batch in order to maximize the throughput. Splitting the image into smaller tiles is especially useful for text detection, the first step in the SayVoca pipeline.
Profiling execution times of low-level tasks and I/O through Furiosa Profiler
When developing this translation feature for the SayVoca Dictionary app, it was important to identify any bottlenecks that impeded performance or increased latency. To do this, we used the Furiosa Profiler as well as open-telemetry-based tools.
Furiosa Profiler allows users to measure execution times of low-level operations running on a CPU and a NPU, as well as I/O between host and devices. A recorded trace is generated in Perfetto proto trace format, and users can view the results in a web browser or the Perfetto UI. The following is a visualized example of a recorded trace. To optimize the latency, we tried to hide I/O times and increase the NPU's computation utilization.
Furiosa-serving also allows users to trace certain spans and export the trace results in the open-telemetry formats. We used an open-telemetry tool to measure elapsed times of different models and their pre/processing steps and then used Prometheus to visualize these trace results as shown in the figure below.
Furiosa's Gen 1 Vision NPU offers a significantly more power efficient solution, which is an important consideration for enterprise customers looking to show their end users that they are environmentally responsible. The NPU delivers a peak performance of 64TOPS (INT8), an aggregate memory bandwidth of 64 GB/s, and a thermal design of just 40-60W (configurable). The card is connected through an 8-channel PCIe Gen4 interface, providing a high performance (16GB/s) interface.
Performance
Compared to NVIDIA’s T4 GPU, one of the most widely used hardware options for AI inference, Furiosa's NPU is more than 20% faster.
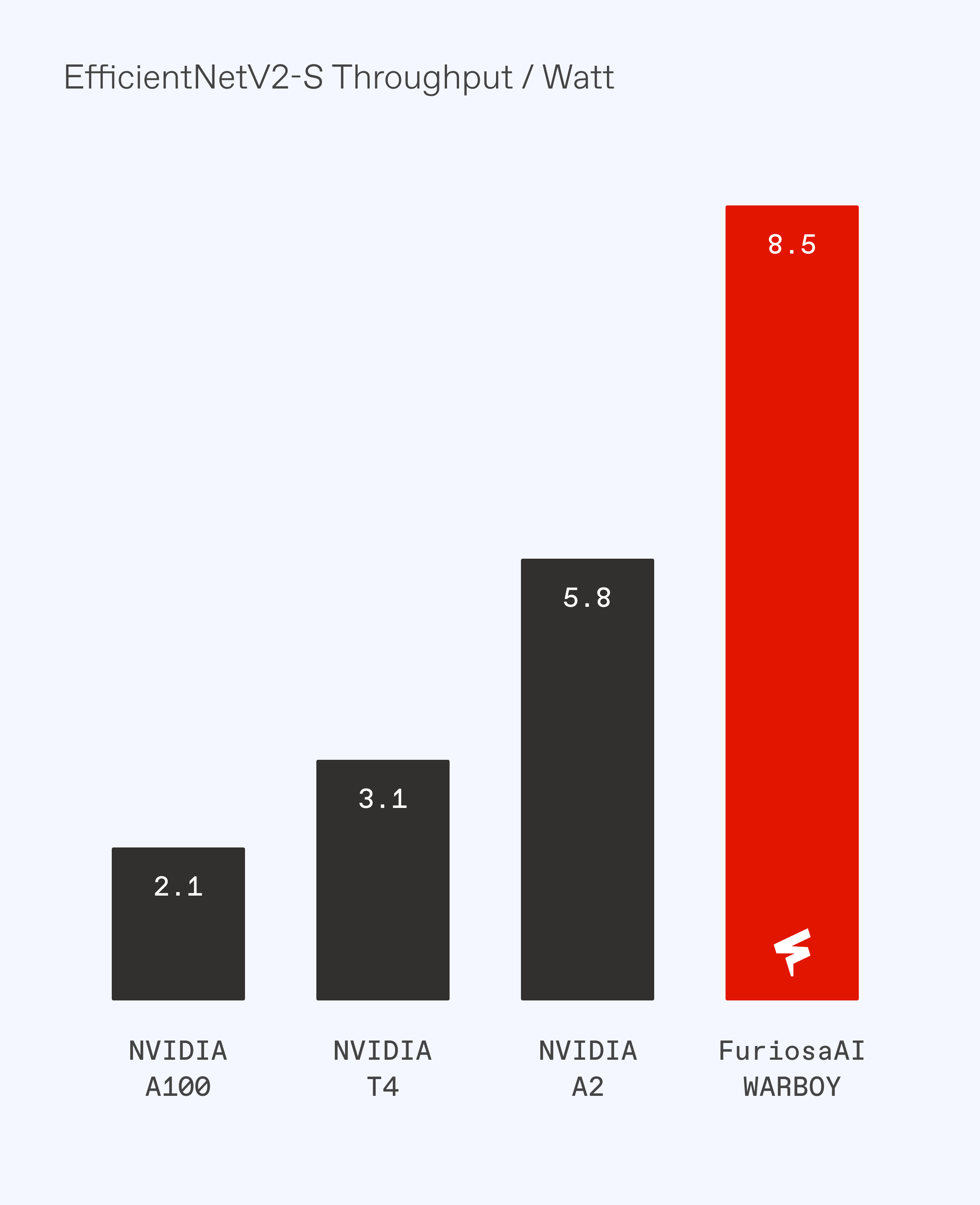
On the EfficientNetV2-S computer vision model, Furiosa's Gen 1 Vision NPU delivers nearly 50% more inferences per watt compared to NVIDIA’s A2, more than double the performance/watt of the T4, and more than 4x more performance than A100.
Overall, SayVoca reported that the new text recognition pipeline delivered an 84% improvement in accuracy over its previous solution.
Conclusion
Compared to a GPU or a CPU, Furiosa's Gen 1 Vision NPU provides strong inference performance at a low price, reducing the operating costs for ePopSoft and allowing the company to reinvest in technology development and infrastructure to provide better services to its users. The NPU can be serviced reliably through a stable infrastructure operated through Kubernetes Infrastructure as Code (KiC).
Furiosa's Gen 1 Vision NPU is available now for computer vision applications including object detection, segmentation, classification, and video superresolution upscaling. Contact us to learn more and arrange a demo. Furiosa’s second-generation chip for generative AI and large language models will launch this year.
Written by
The Furiosa Team


.png)

