The rapid adoption of AI is pushing Kubernetes to evolve. Machine learning models present a different set of challenges for managing clusters, from optimizing resources to supporting new kinds of AI accelerators beyond just GPUs.
This new chapter in Kubernetes' evolution has significant implications for how we run AI workloads at scale, and it's tremendously exciting for companies like FuriosaAI. Our new RNGD chip, designed for high-performance inference with large language models (LLMs) and multimodal models in data centers, leverages the latest Kubernetes advancements to deliver efficient and scalable AI deployments. Thanks to improved functionality in Kubernetes, it is now much easier to manage complex deployments on a variety of hardware – including specialized AI accelerators like RNGD.
In this post, we share insights from Furiosa Senior Engineer Byonggon Chun about the historical challenges that Kubernetes has faced with ML workloads, and how recent innovations like Dynamic Resource Allocation (DRA) and the Container Device Interface (CDI) are solving these problems. We'll also discuss how Furiosa is leveraging these advancements to enable seamless deployment of RNGD for inference at scale.
Furiosa has built an engineering team focused specifically on Kubernetes integration for RNGD. Byonggon brings extensive experience with Kubernetes to this effort. He has been a speaker at the Kubernetes Contributor Summit, and his work has been presented at KubeCon and Samsung Open Source Conference 2019.
Why Kubernetes matters for ML workloads and the challenges it faces
Kubernetes has long been the go-to solution for deploying traditional CPU-based microservices. At its core, it offers:
- Container orchestration at scale
- The ability to manage thousands of containers across server clusters
- Handling of deployment, scaling, and failover
- Resource allocation and load balancing
But the design assumptions that made Kubernetes excellent for standard web services become limitations when working with ML models, especially when deploying them on specialized AI accelerator hardware. It is challenging to effectively manage ML inference workloads at scale with Kubernetes because of issues around resource scheduling, and hardware compatibility.
The challenges of using Kubernetes for AI inference workloads can be divided into two groups:
- Resource management challenges
- Complex hardware topology requirements (such as needing to connect multiple accelerators to the same CPU socket or PCIe switch for optimal performance)
- Limited hardware-aware scheduling (to account for the availability and topology of specialized hardware like AI accelerators)
- Hardware acceleration challenges
- Fragmented container runtime support (where container runtimes like Docker and containerd needed to implement custom code for each type of hardware)
- Inconsistent device exposure methods (making it challenging to build portable applications that could run on different types of AI accelerators without modification)
Recent innovations: DRA and CDI
Several AI chip vendors have been working on Dynamic Resource Allocation (DRA) for several years, but it is now officially a beta feature in Kubernetes.
DRA is a game-changer for managing specialized hardware in Kubernetes, because it provides a much deeper understanding of your hardware's specific needs. Instead of making all scheduling decisions itself, the Kubernetes scheduler can now delegate specific resource allocation tasks to specialized DRA plugins.
In traditional Kubernetes architectures, all scheduling decisions were made by the scheduler. There was no room to intervene in the scheduling process to schedule AI workloads to the right place where all hardware resources are perfectly aligned.
DRA was initially introduced as an alpha feature, but it faced challenges integrating with other Kubernetes components like the Autoscaler. This was primarily due to limitations in how resource requests were described. The alpha version used a simplified model that didn't fully capture the complexities of specialized hardware.
To overcome these limitations, the DRA Alpha API was redesigned to introduce Structured Parameters that can be understood by both the Scheduler and the Autoscaler.
This delivers several important benefits:
- Hardware topology-aware Pod scheduling facilitated by delegated scheduling decisions
- Simplified Resource Management, achieved by hiding complexity of topology-aware device requests and allocations through richer APIs for describing and requesting devices
- Native support of partitionable devices
Misaligned topology can diminish workload performance by 20 percent or more. So these features will have a significant impact – both on systems using GPUs and systems using RNGD and other AI-specific chip architectures.
Another major update is the availability of containerd 2.0. This is important for AI chip vendors because this new version enables CDI, a Cloud Native Computing Foundation (CNCF)-sponsored project that provides a standard specification and interface for container runtimes, by default.
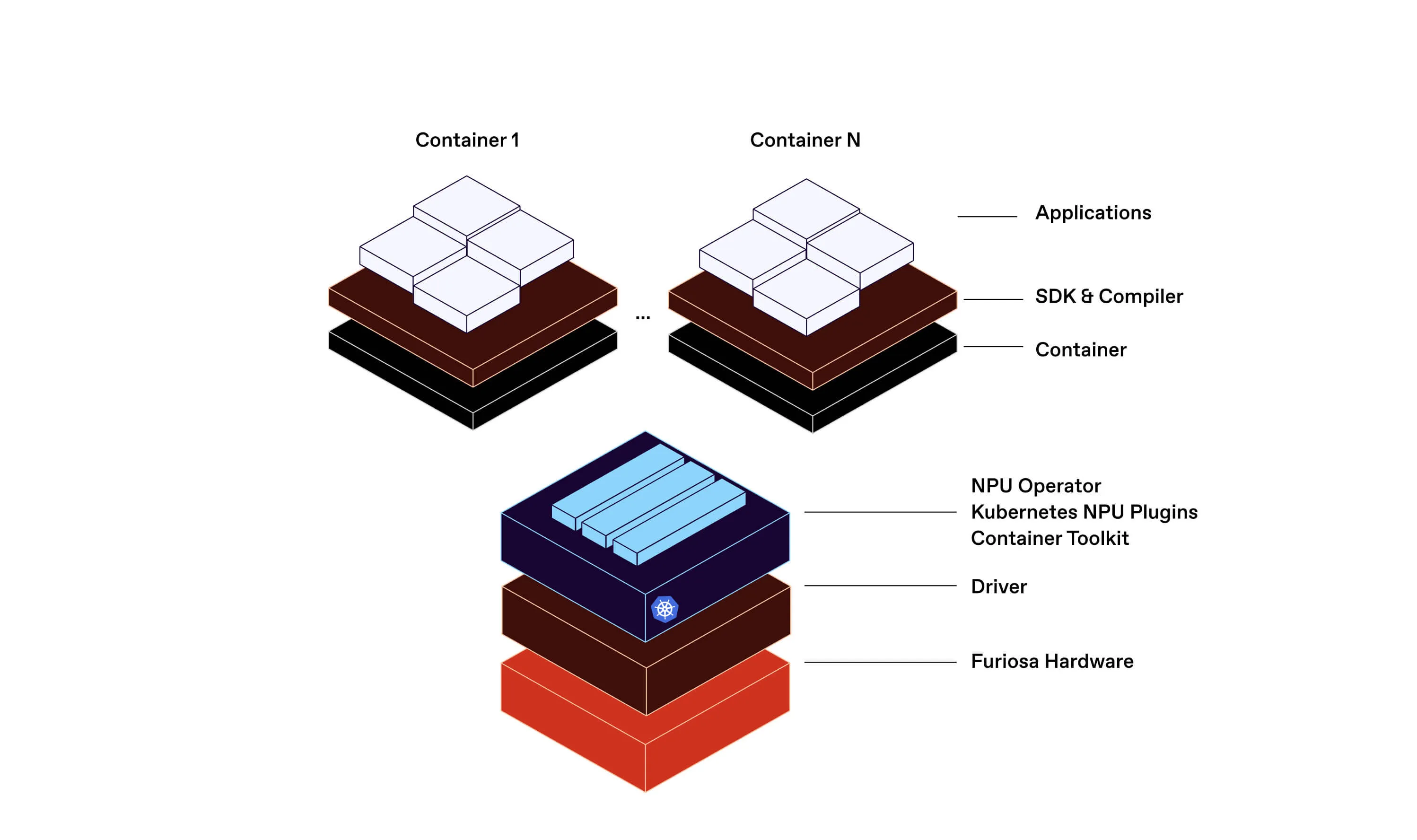
CDI is designed to solve two problems. First, all device vendors expose their devices to containers in different ways. Second, device support in container runtimes is fragmented.
This imposes high costs on both AI chip vendors and the open-source community. Yes, these circumstances clearly illustrate why a standard interface is necessary.
Now AI chip vendors can support various container runtimes through standardized interfaces by implementing CDI. Docker also supports it as an experimental feature, but it is expected to become a default feature in the near future since containerd now supports it as a default feature. Originally, CDI was part of the DRA. However, it now has a greater influence on the entire container ecosystem.
In addition to standardized device exposure, CDI delivers several benefits for enterprise deployments using different kinds of AI hardware (such as RNGD):
- Simplified runtime support
- Standardized interfaces
- Reduced implementation costs
Kubernetes and RNGD
Furiosa has built RNGD to be the best accelerator for real-world deployments using large language models, multimodal models, and agentic AI systems. To achieve this, we will leverage new Kubernetes functionality like CDI and DRA. RNGD uses the CDI to define how devices are assigned to containers.
The CDI specification lays out the format, guidelines, and interfaces needed to properly describe these devices. For example, RNGD’s vendor-specific interfaces like device nodes and sysfs files can be expressed using the interfaces provided by the CDI. This makes it simpler for container-related systems to understand which system resources need to be present when running workloads on RNGD hardware.
We’re currently building a DRA plugin for flexible and efficient resource scheduling. When we release the plugin in 2025, users will be able to request RNGD resources defined through the DRA interface.
One key benefit of DRA is that it allows users to specify their desired hardware topology. For example, a user might say they need four RNGD devices under a single physical CPU socket, or two RNGD devices under a specific PCIe switch. They can even specify that multiple servers must be located beneath a particular network switch.
When the scheduler hands off the RNGD scheduling task to the Furiosa DRA plugin, the plugin calculates which server meets the user’s topology requirements. Among the servers that match these conditions, it then assigns the requested RNGD resources to the user’s container.
Future outlook for Kubernetes and ML workloads
The evolution of Kubernetes, driven by advancements like DRA and CDI, is crucial for the future of AI. As the industry moves beyond traditional GPUs and embraces more efficient chip architectures like RNGD, the ability to effectively orchestrate and manage these resources will become even more critical.
This will accelerate the adoption of specialized hardware, leading to faster, more efficient, and more cost-effective ML inference.
The ongoing collaboration between the Kubernetes community and AI chip vendors is essential to ensure that Kubernetes continues to meet the evolving needs of the AI landscape. By working together, we can unlock the full potential of AI and drive innovation across industries. We believe that sharing our experience with developing and deploying RNGD will contribute to this important effort. We also hope to foster more open-source contributions that will accelerate progress toward an open ecosystem that supports a wide range of AI-specific hardware to serve different needs in the industry.
Written by
The Furiosa Team



